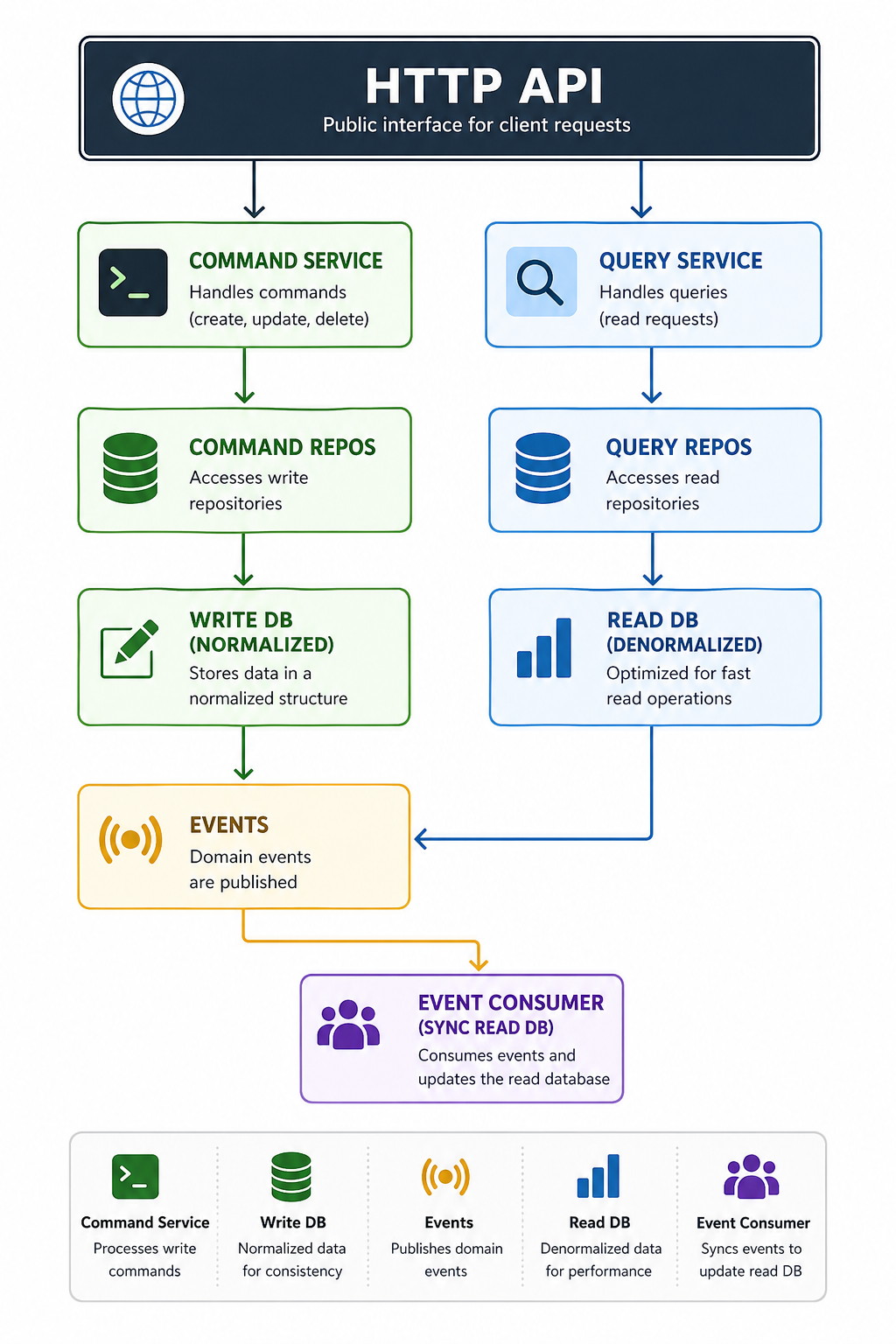
Overview
The Leave Management module implements the CQRS (Command Query Responsibility Segregation) pattern to optimize read performance. During the Better Auth migration, this module was refactored to use PostgreSQL for both command and query models, while relying on Better Auth for identity and role management.Architecture
Components
1. Read Models (Denormalized)
LeaveRequestReadModel:
- Denormalized with user info (name, email)
- Denormalized with leave type info (name, code)
- Includes computed fields:
year,month,is_active - Optimized for fast queries
LeaveBalanceReadModel:
- Denormalized with user and leave type info
- Includes computed fields:
usage_percentage= (used_days / total_days) * 100is_low_balance= remaining_days < 3
- Enables quick dashboard queries
2. Query Repositories
LeaveQueryRepository:
FindRequestsByUser- Get all requests for a userFindRequestsByStatus- Filter by PENDING/APPROVED/REJECTEDFindRequestsByDateRange- Filter by date rangeFindPendingRequests- Quick access to pending requests
LeaveBalanceQueryRepository:
FindBalancesByUser- Get all balances for a userFindLowBalances- Find users with low balances (< 3 days)
3. Query Service
LeaveQueryService:
ListUserLeaveRequests- Paginated user requests with filtersListPendingRequests- Paginated pending requestsGetUserBalances- Get all balances for a userListLowBalances- Paginated low balance alerts
4. Event Consumer
LeaveConsumer:
- Listens to
LeaveRequestCreatedevents - Listens to
LeaveBalanceUpdatedevents - Automatically syncs read models when write operations occur
- Ensures eventual consistency
Benefits
✅ Performance
- Fast Reads: Denormalized data eliminates joins
- Optimized Indexes: Read collections can have different indexes
- Computed Fields: Pre-calculated values (usage_percentage, is_low_balance)
✅ Scalability
- Separate Scaling: Read and write databases can scale independently
- Read Replicas: Easy to add read replicas for query workload
- Caching: Read models are cache-friendly
✅ Flexibility
- Different Data Models: Write model (normalized) vs Read model (denormalized)
- Query Optimization: Each query can have its own optimized structure
- Multiple Read Models: Can create different read models for different use cases
Collections
Write Tables (Normalized - Postgres)
Read Tables (Denormalized - Postgres)
Identity Tables (Read-Only - Better Auth)
Usage Examples
Command (Write)
Query (Read)
Event Flow
- Command → Write to normalized DB → Publish event
- Event Consumer → Listen to event → Update read model
- Query → Read from denormalized DB → Return fast results
Indexes (Recommended)
leave_requests_read
leave_balances_read
Next Steps
- Publish Events: Update
LeaveServiceto publish events when creating/updating requests - Add Indexes: Create database indexes for optimal query performance
- Add Query Endpoints: Create HTTP handlers for query operations
- Monitoring: Add metrics for read/write performance
- Caching: Add Redis caching layer for frequently accessed queries
Trade-offs
Pros
- ✅ Extremely fast reads
- ✅ Scalable architecture
- ✅ Flexible query models
Cons
- ❌ Eventual consistency (small delay between write and read)
- ❌ More complex (two data models to maintain)
- ❌ Storage overhead (data duplication)